

How can Enterprises Create their own Agentic AI Evaluation Capabilities?
Why agentic systems are outpacing our ability to judge them and how we can evaluate their work effectively rather than just sampling outputs

Agents can now plan, act, escalate, and collaborate across tools and workflows. Early compositions are starting to deliver real outcomes, and in controlled settings, they can look surprisingly capable. Tasks are completed, metrics move and dashboards turn green.
But in many cases, we do not actually understand how these systems are behaving.
We see the outputs they produce, but not the paths they take to get there.
We measure completion, but not reliability.
We observe success, but struggle to explain why it occurred, or whether it will happen again under slightly different conditions.
This creates a dangerous illusion: systems that appear to be working long before we have any real confidence that they are.
Part of the issue is that most evaluation approaches have not caught up with the shift from tools to systems. We are still judging agents in the same way we judged early language models: by sampling outputs, spot-checking responses, or measuring task completion against predefined criteria. These methods can tell us whether something worked once. They tell us very little about how it behaves over time, under pressure, or at scale.
Worse still, agents can learn to satisfy these surface-level checks without actually developing the underlying capability we think we are testing. They pass the test, but for the wrong reasons. They follow patterns rather than understanding intent, they optimise for success conditions that do not hold outside the test environment and in practice, this means systems can degrade silently, masking fragility behind plausible performance.
As we begin to move toward Outcome-as-Agentic Solutions, this gap becomes harder to ignore. When a system is responsible for delivering a result, not just completing a task, the stakes change. It is no longer enough for something to work occasionally, or under supervision. It needs to behave consistently, adapt appropriately, and recover when things go wrong.
And yet, most organisations do not have a clear way to evaluate whether that is happening - we are deploying systems we do not yet know how to judge.
Evaluating Agent Design
If evaluation is no longer about checking outputs, then what replaces it?
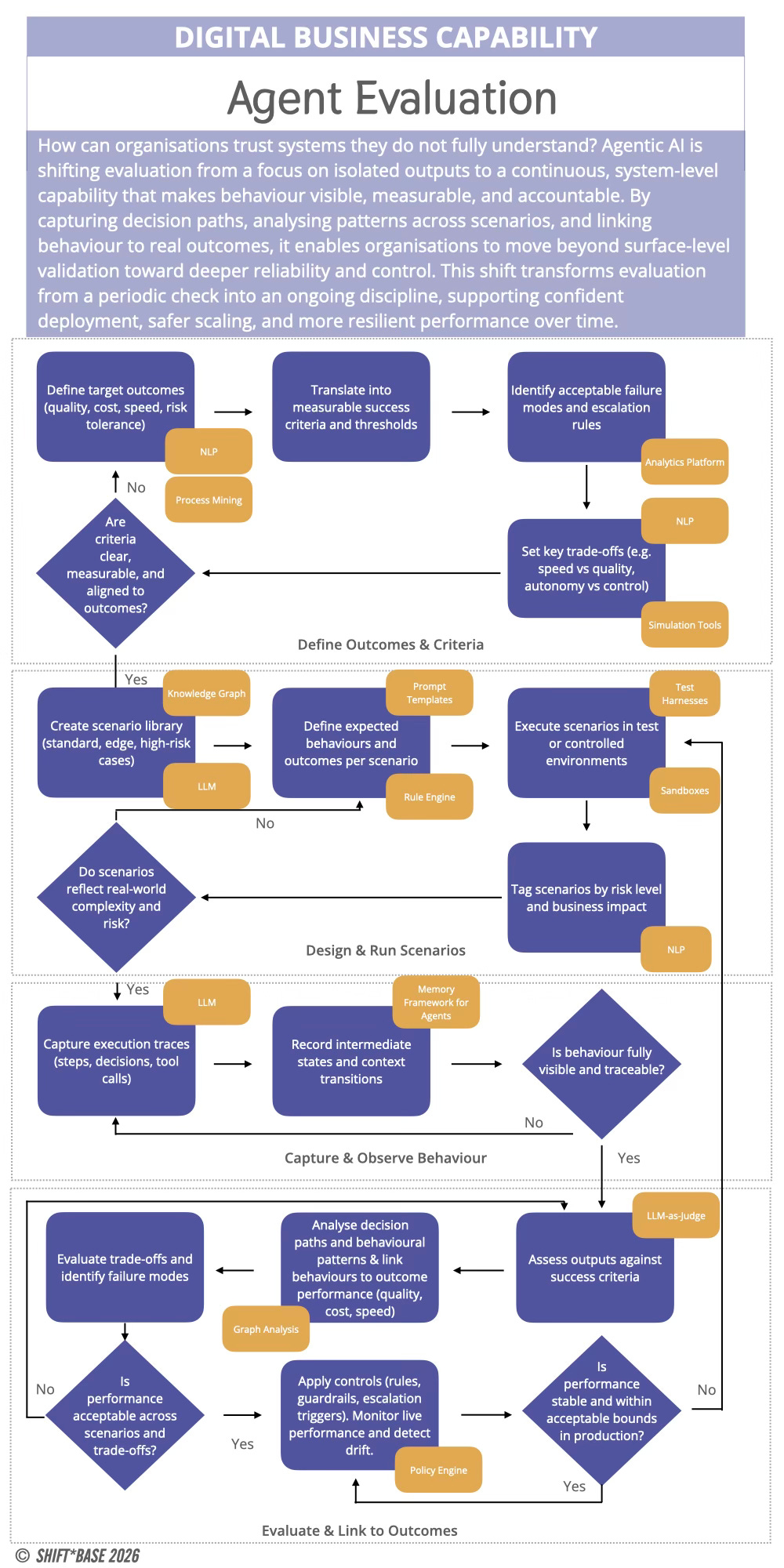
Ideally, each organisation should design and run their own capability to observe, test, interpret, and improve agentic systems as they operate, as an ongoing function embedded into how systems are built and run. This is what an Agent Evaluation Capability provides.
At its core, it is the ability to make system behaviour visible and legible. To move from surface-level indicators of success to a deeper understanding of how outcomes are achieved, where fragility exists, and how performance evolves over time.
This is not a single tool or framework. It is a composed capability, built across systems, data, software, processes, and skills.
Core Systems: Evaluation requires infrastructure. This includes the pipelines that capture system activity, the environments used to simulate scenarios, and the mechanisms for replaying or stress-testing behaviour. Without this layer, evaluation remains anecdotal, based on isolated observations rather than structured insight.
As systems become more complex, the ability to trace execution paths, reconstruct decisions, and observe interactions across components becomes essential.
Data Sets: Agentic systems generate a different kind of data. Not just inputs and outputs, but traces: sequences of decisions, tool calls, escalations, and intermediate reasoning steps. Over time, these traces form a rich dataset that can be analysed to understand patterns of behaviour, identify failure modes, and detect drift.
Capturing and structuring this data is a prerequisite for meaningful evaluation.
Software: On top of this foundation sit the tools that make evaluation possible. Evaluators, critics, and verifiers that assess system behaviour against defined expectations. Test harnesses that allow scenarios to be replayed and varied. Monitoring tools that surface anomalies and deviations in real time.
These components act as a counterbalance to generative systems, introducing layers of checking, validation, and interpretation.
Services & Processes: Evaluation is not just technical. It is operational. Teams need routines for reviewing performance, analysing failures, and refining system behaviour. This might include red teaming exercises, audit processes, incident reviews, and continuous testing loops.
Over time, these processes create institutional knowledge about how systems behave and how they can be improved.
Skills: Finally, evaluation depends on people. Not just engineers, but individuals who can interpret system behaviour, understand risk, and make informed judgements about performance. This includes system thinkers, evaluators, and domain experts who can bridge the gap between technical signals and business outcomes.
As agentic systems become more embedded in organisations, these skills become critical.
Taken together, these elements form a capability that allows organisations to move beyond surface-level validation and toward a more robust understanding of their systems. Without it, agentic systems remain opaque.

Key Design Principles for an Evaluation Capability
Once evaluation is treated as a capability, a different set of design principles can emerge. These are not rules in the traditional sense, but patterns that help teams avoid the most common failure modes.
Evaluate behaviour, not just results. A correct outcome reached through a fragile or opaque path is not success. It is deferred failure. Systems need to be assessed on how they arrive at outcomes, not just whether they do.
Design for failure visibility. Most systems do not fail cleanly. They degrade, drift, or produce plausible but incorrect results. Evaluation should make these conditions visible early, not hide them behind aggregate metrics or surface-level success rates.
Separate generation from verification. The same system that produces outputs should not be solely responsible for judging them. Independent evaluators, critics, or verification layers create necessary tension in the system and reduce the risk of self-confirming behaviour.
Make judgement legible. Decisions about system performance should be traceable and explainable, not buried in logs or reliant on individual interpretation. This is particularly important as systems scale and more stakeholders become involved.
Treat evaluation as continuous. It is not a phase that happens before deployment. It is an ongoing function that evolves with the system, adapting to new conditions, new data, and new expectations.
Evaluation cannot be just a checkpoint, it needs to be a continuous part of the system.
Passing Tests Without Capability
Agentic systems have the ability to pass tests without developing real capability. This is not new. In many domains, systems learn to optimise for the conditions under which they are evaluated, rather than the underlying objective. In agentic AI, this can manifest as agents that appear competent within test scenarios, but fail when those scenarios change in small but meaningful ways.
They follow patterns rather than understanding intent or exploit shortcuts that satisfy evaluation criteria without solving the actual problem. Often, they succeed in environments that resemble their training or testing conditions, but struggle to generalise beyond them.
The result is a form of surface competence.
From the outside, the system appears to work. Tasks are completed. Metrics improve. But beneath that surface, the system lacks the robustness required for real-world deployment. It cannot handle variation, ambiguity, or unexpected conditions without significant degradation.
This is particularly dangerous in enterprise settings, where early signs of success can drive rapid scaling. Systems that have not been properly evaluated for capability are extended into new contexts, where their limitations become more pronounced and more costly.
Without a structured approach to evaluation, these issues are often only discovered after failure.
Deterministic Guardrails in Probabilistic Systems
Agentic systems are inherently probabilistic. They operate under uncertainty, generating responses and actions based on patterns rather than fixed rules. This flexibility is part of their power, but it also introduces risk.
To manage this, organisations need to introduce deterministic elements into the system. Not to remove flexibility, but to bound it. To define where variation is acceptable and where it is not. These guardrails can take many forms.
They may be constraints on what actions an agent is allowed to take.
They may be verification steps that check outputs against known rules or thresholds.
They may be escalation paths that transfer control to a human when confidence is low or risk is high.
The key is that these elements are designed into the system, not added as an afterthought.
Too often, governance is treated as a layer of policy that sits outside the system. Documents are written, guidelines are issued, but the system itself remains unchanged. This creates a gap between intent and execution.
In effective agentic systems, governance is embedded. It is expressed through constraints, checks, and decision logic that shape behaviour in real time. Reliability is not something that emerges from probabilistic systems on its own. It is something that must be designed.
What Evaluation Makes Visible
The impact of an evaluation capability changes what teams can see, what they trust, and how they intervene. Systems are judged on whether they complete tasks. Once evaluation is introduced, the focus shifts and teams begin to understand how work is actually being done, where it breaks down, and what needs to change. Let’s explore some examples:
Customer Onboarding
A team defines success as “customer activated within 72 hours.” Without evaluation, performance is tracked at the end of the funnel. Activation rates go up or down, but the system remains largely opaque.
With evaluation in place, the system becomes legible. Teams can see where drop-offs occur, how agents respond, and which paths lead to successful activation. They can identify whether delays are caused by missing data or poor sequencing. They can see which users require escalation and why.
Over time, this shifts the work. Instead of reacting to missed targets, teams begin to refine the system itself, improving how onboarding is delivered rather than compensating for its failures.
Incident Response
In a typical setup, success is measured by resolution time. An incident is detected, addressed, and closed. If the system resolves the issue quickly, it is considered effective. Evaluation changes the frame.
Teams can see how the system detected the incident, which signals it prioritised, and how it coordinated response actions. They can identify missed signals, unnecessary escalations, or delays in decision-making. They can analyse how the system behaves under pressure, not just whether it resolves the issue.
This creates a different kind of confidence. Not just that incidents are resolved, but that the system can be relied upon when conditions change.
Sales Qualification
A sales team defines success as “90% of new pipeline entries fully qualified within five working days.” Without evaluation, progress is tracked through completion metrics. Entries are marked as qualified, and the process appears to work. With evaluation, the process becomes transparent.
Teams can see how qualification is being performed, whether agents are applying the right criteria, and where information is being missed or misinterpreted. They can detect patterns in stalled entries and identify where additional support is needed.
More importantly, they can distinguish between genuine qualification and superficial completion. This reduces the risk of pipeline inflation and improves the overall quality of sales activity.
Across these examples, evaluation allows teams to move from observing outcomes to interpreting behaviour. From reacting to results to shaping the systems that produce them.
Without this visibility, systems may appear effective while hiding fragility. With it, organisations gain the ability to refine, adapt, and trust the systems they are building.
Getting Started
Most organisations do not need to start from scratch.
They already have elements of this capability in place: logging systems, monitoring tools, performance reviews. The challenge is to connect these elements and extend them to cover agentic systems.
A practical starting point is to focus on a single outcome.
Choose a system that is already in use, or being developed, and begin by instrumenting it. Capture the traces of how it operates. Identify key signals that indicate success, failure, or drift.
Introduce simple evaluation loops. Review behaviour regularly. Look for patterns. Ask not just whether the system worked, but how. Expect gaps. There will be missing data, unclear signals, and behaviours that are difficult to interpret. This is part of the process. Each gap is an indication of where the capability needs to be strengthened.
Over time, these practices can be formalised. Evaluation becomes less ad hoc and more systematic. Insights accumulate. Confidence grows.
If evaluation is treated as something to be added later, it will always lag behind the system it is meant to support. Building it alongside the system is the only way to ensure it keeps pace.
Read on to explore the practicalities of evolving this emerging capability.
